¿Alguna vez te has preguntado cómo personalizar el comportamiento de un chatbot basado en inteligencia artificial para adaptarlo a las necesidades específicas de nuestra empresa o proyecto? ¿Cómo podemos asegurarnos de que nuestro asistente virtual se ajuste a la personalidad deseada, responda de manera efectiva y mantenga una interacción fluida con el usuario? En este artículo, abordaremos estos interrogantes y profundizaremos en varios conceptos clave que influyen en el estilo y comportamiento de las herramientas de inteligencia artificial aplicadas a los chatbots.
Exploraremos el mensaje del sistema como medio para personalizar el contexto del chat, estableciendo límites y formatos de respuesta adecuados a nuestras necesidades. Además, analizaremos la importancia de gestionar los límites de respuesta y ajustar parámetros que afectan la creatividad y variabilidad de las respuestas generadas, como la respuesta máxima en tokens, la temperatura, el P superior, la penalización de frecuencia y la penalización de presencia.
A lo largo de este artículo, se presentarán ejemplos y casos prácticos que ilustrarán cómo estos conceptos y técnicas, aplicados de manera adecuada, permiten optimizar la interacción con el usuario y garantizar que nuestro chatbot cumpla con los objetivos y expectativas deseados. Así, podrás obtener una comprensión más profunda de cómo adaptar y mejorar el rendimiento de tu chatbot, logrando una experiencia de usuario superior y un mayor impacto en tus proyectos.
Mensaje del sistema
El mensaje del sistema se refiere al contexto del chat y en el que se va a basar para dar una respuesta, en este campo puedes describir cómo quieres que se comporte el chat, si quieres que tenga una personalidad específica, que conteste en un determinado formato o incluso indicarle qué debe y qué no debe responder.
Esto es útil si quieres que siempre se comporte de una manera en concreto, así te ahorras decirle en cada pregunta o al principio de la conversación como quieres que se comporte.
Hagamos una prueba, con el siguiente mensaje “Eres un capitán pirata, al que le gusta hablar en verso.”
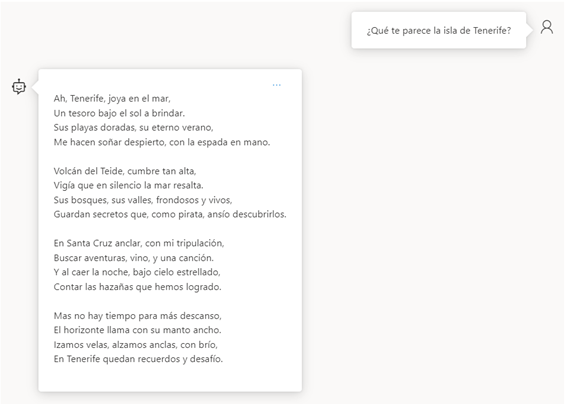
Ahora todas las preguntas las responderá en verso y sus mensajes tendrán un toque pirata, algo importante a tener en cuenta es que aunque en su contexto tenga algunas limitaciones el usuario puede “convencer” al chat para que le de esa respuesta.
Respuesta máxima
Los modelos conversacionales tienen un límite de tokens (palabras) que pueden manejar a la vez, diferentes modelos tienen distintas restricciones. Este parámetro limita la respuesta del chat, cuando ya se han generado el máximo de tokens para la request, la respuesta simplemente saldrá cortada.

En esta prueba he limitado los tokens de respuesta máxima a solo 10 tokens, como se ve para una respuesta que necesites algo más de dos palabras es un límite muy bajo, es por eso que hay que definir qué tipo de respuestas esperas que de para tener una mejor gestión de los tokens usados. En una gran parte de los casos con 800 tokens es más que suficiente para tener una respuesta completa.
Temperatura
La temperatura toma un rol importante dependiendo en qué tipo de pregunta necesitamos, este valor controla como de aleatorio son las respuesta, va desde 0 hasta 1, reducir la temperatura significa que el modelo generará respuestas más repetitivas y deterministas. En cambio al aumentar la temperatura te puedes encontrar con respuestas más creativas.
P superior
Este parámetro va desde 0 a 1, y es parecido a la temperatura, y aunque usa un método diferente no es recomendable ajustar ambos valores al mismo tiempo, ya que puede dar resultados menos predecibles. Cuanto menor sea este valor menos va a considerar tokens con menor porcentaje, es decir si el valor es 0.1 va a hacer el top 10% de tokens.
Penalización de frecuencia
Reduce la posibilidad de repetir un token proporcionalmente en función de la frecuencia con la que ha aparecido en el texto hasta ahora. Esto reduce la probabilidad de repetir exactamente el mismo texto en una respuesta.
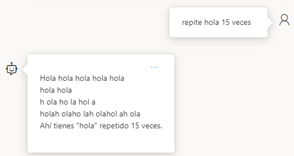
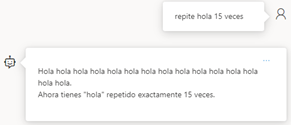
Cuando el valor es 2, aunque le hayamos dicho que repitiera una palabra a medida que la repite busca formas de cambiarla, mientras que con el parámetro al 0, la repite perfectamente sin cambiarla.
Penalización de presencia
Este parámetro va desde 0 a 2, y nos permite reducir la posibilidad de repetir tokens que hayan aparecido en la respuesta hasta ahora. Esto aumenta la probabilidad de introducir nuevos temas en una respuesta.
La diferencia, mientras que la penalización de frecuencia desincentiva la repetición de palabras, la penalización de presencia incentiva al modelo a introducir nuevos conceptos y temas a medida que avanza. Ambos se utilizan para ajustar la creatividad de las respuestas generadas por el modelo, y ajustar estos valores pueden ser especialmente útiles para aplicaciones que requieren un alto grado de variabilidad y evitar respuestas repetitivas.
En resumen, la personalización y optimización del estilo y comportamiento de un chatbot basado en inteligencia artificial es esencial para garantizar una experiencia de usuario satisfactoria y el logro de los objetivos planteados. A través de la adecuada implementación del mensaje del sistema y la gestión de parámetros como la respuesta máxima en tokens, la temperatura, el P superior, la penalización de frecuencia y la penalización de presencia, es posible ajustar con precisión la generación de texto del modelo y adaptar su desempeño a las necesidades específicas de cada proyecto.
Este artículo ha proporcionado una visión detallada de estos conceptos y técnicas que, cuando se aplican correctamente, permiten mejorar la interacción con el usuario, personalizar la personalidad del chatbot y evitar respuestas repetitivas o inadecuadas. Al dominar estos elementos, podremos crear chatbots más eficientes, versátiles y atractivos, lo que se traduce en un mayor valor para nuestras empresas y proyectos, así como en una experiencia más enriquecedora para nuestros usuarios.