Have you ever wondered how to customize the behavior of an AI-based chatbot to adapt it to the specific needs of our company or project? How can we make sure that our virtual assistant fits the desired personality, responds effectively and maintains a smooth interaction with the user? In this article, we will address these questions and delve into several key concepts that influence the style and behavior of artificial intelligence tools applied to chatbots.
We will explore the system message as a means to personalize the chat context, setting boundaries and response formats appropriate to our needs. In addition, we will analyze the importance of managing response limits and adjusting parameters that affect the creativity and variability of the generated responses, such as maximum response in tokens, temperature, upper P, frequency penalty and presence penalty.
In this article, we will present examples and case studies that will illustrate how these concepts and techniques, properly applied, allow you to optimize user interaction and ensure that your chatbot meets your desired goals and expectations. Thus, you will be able to gain a deeper understanding of how to adapt and improve the performance of your chatbot, achieving a superior user experience and a greater impact on your projects.
System Message
The system message refers to the context of the chat and what it will rely on to give an answer, in this field you can describe how you want the chat to behave, whether you want it to have a specific personality, answer in a certain format or even tell it what it should and should not answer.
This is useful if you want it to always behave in a particular way, so you can avoid telling it in each question or at the beginning of the conversation how you want it to behave.
Let's do a test, with the following message "You are a pirate captain, who likes to speak in verse."
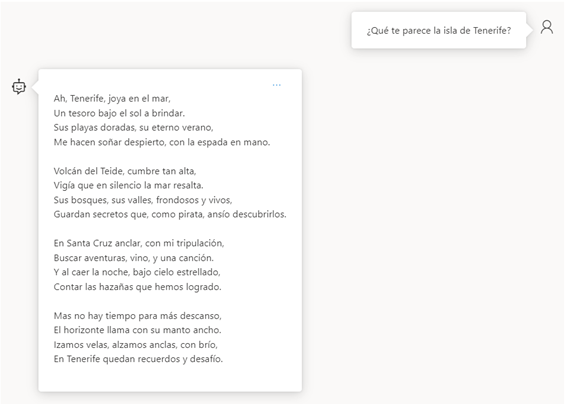
Now all the questions will be answered in verse and your messages will have a pirate touch, something important to take into account is that although in its context it has some limitations the user can "convince" the chat to give him that answer.
Maximum Response
Conversational models have a limit of tokens (words) they can handle at a time, different models have different restrictions.
This parameter limits the chat response, when the maximum tokens have already been generated for the request, the response will simply be cut off.

In this test we have limited the maximum response tokens to only 10 tokens, as you can see for a response that needs a little more than two words is a very low limit, that is why you have to define what kind of responses you expect to get to have a better management of the tokens used. In most cases 800 tokens is more than enough to have a complete answer.
Temperature
The temperature takes an important role depending on what kind of question we need, this value controls how random the answers are, it goes from 0 to 1, reducing the temperature means that the model will generate more repetitive and deterministic answers.
On the other hand, by increasing the temperature you can find more creative answers.
Top P
This parameter ranges from 0 to 1, and is similar to the temperature, and although it uses a different method it is not recommended to adjust both values at the same time, as it may give less predictable results. The lower this value the less it will consider tokens with lower percentage, i.e. if the value is 0.1 it will make the top 10% of tokens.
Frequency Penalty
It reduces the chance of repeating a token proportionally based on how often it has appeared in the text so far. This reduces the probability of repeating exactly the same text in an answer.
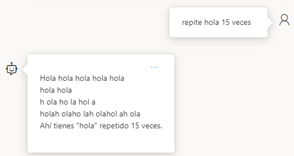
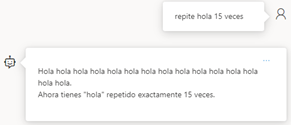
When the value is 2, even if we have told it to repeat a word as it repeats it, it looks for ways to change it, whereas with the parameter at 0, it repeats it perfectly well without changing it.
Presence Penalty
This parameter ranges from 0 to 2, and allows us to reduce the chance of repeating tokens that have appeared in the answer so far. This increases the probability of introducing new topics in an answer.
The difference lies in the fact that while the frequency penalty discourages the repetition of words, the presence penalty encourages the model to introduce new concepts and topics as it progresses. Both are used to adjust the creativity of the responses generated by the model, and adjusting these values can be especially useful for applications that require a high degree of variability and avoid repetitive responses.
In summary, customizing and optimizing the style and behavior of a chatbot based on artificial intelligence is essential to ensure a satisfactory user experience and the achievement of the stated objectives. Through the proper implementation of the system message and the management of parameters such as maximum token response, temperature, upper P, frequency penalty and presence penalty, it is possible to fine-tune the model's text generation and adapt its performance to the specific needs of each project.
This article has provided a detailed overview of these concepts and techniques that, when applied correctly, allow us to improve user interaction, personalize the chatbot's personality and avoid repetitive or inappropriate responses. By mastering these elements, we will be able to create more efficient, versatile and engaging chatbots, which translates into greater value for our companies and projects, as well as a more enriching experience for our users.