Some time ago we published in this blog an article, the work of our phenomenal colleague Victor Rodilla, on the implementation of a solution for disaster recovery of IT infrastructure, a solution called Azure Site Recovery.
Azure Site Recovery allows to protect all or part of an IT infrastructure, so that, in the event that such infrastructure suffers a failure that prevents its proper functioning, the same can be raised but in another physical location. This means that an organization or individual can continue to offer IT services without having to suffer dramatic downtime.
The article that was prepared to implement Azure Site Recovery covers its deployment in a standard way, but we wanted to complement it with this one.
Motivations:
Nowadays, IT processes have taken on enormous importance, to such an extent that a single failure in their workflow can mean very appreciable losses, making it necessary to protect these processes. The usual method is to have another infrastructure in another physical location, away from the main site, and ready to be put into operation in case of problems. This, in effect, entails additional expense, to such an extent that it could be considered as a second copycat DPC.
Over time, with the increasing use of virtualization, this has led to the use of software capabilities in an increasing number of tasks, including the recovery of IT processes in the event of disasters, which has also resulted in lower costs.
And finally, with the rise of cloud technology (mainly supported by the use of virtualization), the development of a disaster recovery plan is within the reach of more and more people and organizations, greatly facilitating its implementation.
Some interesting facts...
The data below is a perfect reflection of not using and/or not having a disaster recovery plan in place:
- 75% of small businesses have no disaster recovery plan at all.
-
Hardware failures cause 45% of IT service losses, followed by 35% for loss of power supply, 34% for software failures, 24% for data corruption, 23% for external security breaches and 20% for human failures, with more than one event occurring simultaneously.
-
93% of companies that suffered an infrastructure failure and did not have a disaster recovery plan fell below expectations for 1 year or more.
-
However, when companies did have some form of disaster recovery plan in place, 96% were able to withstand a variety of attacks in the IT world, but primarily ransomware.
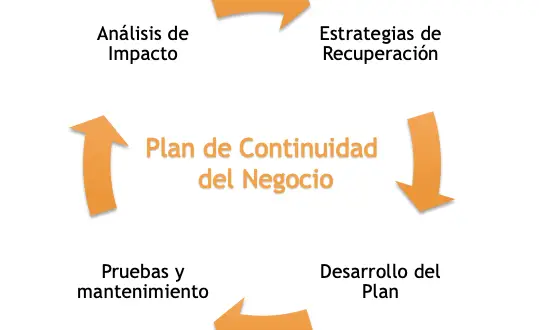
The business continuity plan is a virtuous circle, in which you are constantly investigating and solving
constantly investigating and resolving possible future problems.
Backup or disaster recovery:
However, all of the above seems to be common to another great concept about information recovery: backups. What are the differences?
Knowing that both concepts refer, essentially, to the recovery of information, the differences between one and the other lie in two premises: the time backward in the recovery and the point where to perform it. These are explained below:
- Time backward refers to the interval at which a user will go backward in order to recover something. While backups are set up to back up information that is assumed to be important over a long period of time, disaster recovery only does so for very recent information. Indeed, the goal of disaster recovery is simply "to recover as soon as possible the service you were working with; not so much any information that is supposed to be important, but all the information you were dealing with as close as possible in time.
- As for the point of recovery, it is curious that one is the inverse of the other: the backup is always performed in the same place where the information was lost, while disaster recovery is performed in another place, physically far away from the place where the information was lost.

The two concepts are not mutually exclusive, in the sense that it is possible to develop a very robust information protection plan that combines both concepts.
Long-term vision:
Having said all of the above, and as technology advances in its global implementation, we should not even think that the loss of any service or information was something normal. On the contrary, this should be something "out of the ordinary" and "unexpected". The deployment of a disaster recovery system should be a standard norm for any IT implementation, from a simple local server to a complete worldwide segmented infrastructure.
At this point, I pose a question: should we consider the Earth as the natural limit of the digital world? Or could we increase this limit, this horizon? Indeed, the Moon is the next target in order to advance the expansion of the human race, so deploying some kind of information backup infrastructure should not be so far-fetched. On the contrary, it should be considered by Microsoft, or any computer company, to push the limit further, to where no one has gone before.

Konstantin Tsiolkovsky once enunciated that "the earth is the cradle of the human species, but we cannot always stay in a cradle...".
but we cannot always stay in a cradle...". With the recent problems of availability and
supply, it should become increasingly important to expand humanity's horizon.
The usefulness of the use of solar energy in the generation of electricity supply at the lunar poles could be investigated; once this usefulness is known, and its implementation is well controlled, the way would be paved to start building computer infrastructure at the aforementioned poles. Something like this could serve as a first action for future human expansion. As a final comment, the motive for Microsoft exists, it has the opportunity to use its means, resources, knowledge and research to carry it out, even if it were only the first step. Now it only remains to take it...